
Hadoop i NoSQL przechowują i przetwarzają dane na standardowym sprzęcie. Oba narzędzia rozszerzają i unowocześniają klasyczną koncepcję hurtowni danych.
Do tej pory firmy polegały na technikach hurtowni danych, aby uzyskać ważne informacje o swojej bieżącej działalności ze swoich systemów informatycznych. Ostatnio takie podejście zostało wyprzedzone przez rzeczywistość. Podczas normalnej działalności biznesowej firmy każdego dnia generowane są ogromne ilości danych - czy to z produkcji, obecności w Internecie, czy też danych z czujników z urządzeń mobilnych i maszyn.
Właściwe narzędzie do Big Data: Wybór właściwych narzędzi opiera się na kryteriach różnorodności danych i szybkości, z jaką powinny być dostępne wyniki. W takim scenariuszu każdego dnia można utworzyć 100 milionów nowych rekordów. Przetwarzanie za pomocą klasycznej technologii hurtowni danych szybko osiąga swoje granice w tym środowisku. Szczególnie działy specjalistyczne są pod presją konieczności oceny informacji z operacji biznesowych niemal w czasie rzeczywistym, co nie jest możliwe w przypadku klasycznej metody.
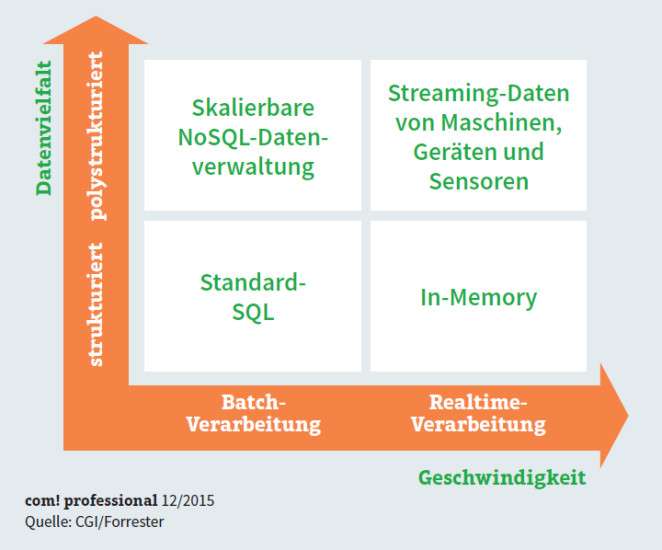
Nowe podejścia do Big Data obiecują spełnienie zmienionych wymagań. Należą do nich narzędzia takie jak NoSQL i Hadoop, dzięki którym klasyczna koncepcja hurtowni danych może zostać rozbudowana i unowocześniona.
Relacyjne bazy danych – ponieważ są wykorzystywane w hurtowniach danych – mogą mieć problemy z wydajnością pod obciążeniem. Typowymi przykładami są aplikacje do strumieniowego przesyłania multimediów lub witryny internetowe o dużym natężeniu ruchu. Powód: od pewnego momentu dodatkowy wysiłek administracyjny wymagany do skalowania z systemami SQL powoduje, że zalety SQL stają się negatywne, a wydajność znacznie spada. Dotyczy to tym bardziej, im większa staje się potrzeba skalowania.
Skalowalność baz danych: przy dużej ilości danych wydajność tradycyjnych baz danych SQL znacznie spada, podczas gdy w przypadku baz danych NoSQL pozostaje prawie taka sama. Bazy danych NoSQL (nie tylko SQL) lepiej radzą sobie z tymi wymaganiami. Z jednej strony działają na standardowym sprzęcie, az drugiej są skalowalne w poziomie, co oznacza, że mogą przetwarzać duże ilości danych w opłacalny sposób. Ważnymi przedstawicielami tego typu baz danych są MongoDB, Cassandra, CouchDB czy Neo4j.
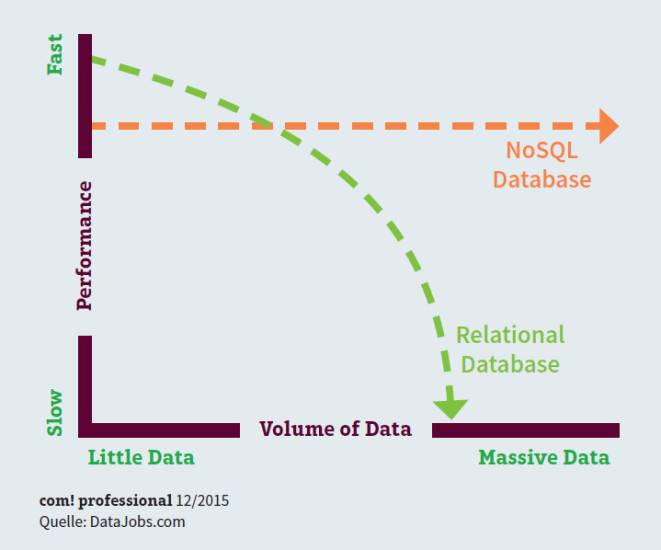
Ze względu na swoją skalowalność i elastyczność systemy NoSQL są idealnie dopasowane do wymagań big data.
Główną wadą NoSQL jest jednak możliwość zapytania o przechowywane dane. W przeciwieństwie do relacyjnych baz danych, w których istnieje jednolity i bardzo wydajny język zapytań SQL, NoSQL nie miał do tej pory jednolitego standardu we wszystkich bazach danych. W przypadku takich funkcji, jak raportowanie ad hoc, kokpity menedżerskie i analizy OLAP, SQL nadal odgrywa ważną rolę. Jednak systemy NoSQL można również łączyć z technologią hurtowni danych, aby czerpać korzyści z obu podejść, co jest szczególnie interesujące dla dziedzin specjalistycznych.





Leave a Comment